
OpenAI, AI modellerinin kritik güvenlik değerlendirmelerinde nasıl performans gösterdiğini şeffaf bir şekilde paylaşmak için tasarlanmış özel bir platform olan “Güvenlik Değerlendirmeleri Merkezi”ni tanıttı. Bu girişim, kullanıcılara, araştırmacılara ve politika yapıcılara zararlı içerik üretimi, jailbreak’lere karşı duyarlılık ve halüsinasyonların oluşumu ile ilgili modellerin davranışları hakkında içgörüler sağlamayı amaçlıyor.
Güvenlik Değerlendirmeleri Merkezi dört temel alana odaklanıyor:
- Zararlı İçerik: Modelin nefret söylemi veya yasadışı tavsiye gibi OpenAI politikalarını ihlal eden içerik üretmeye direnme yeteneğini değerlendirme.
- Jailbreak’ler: Modelin güvenlik önlemlerini atlatmak ve zararlı çıktılar oluşturmak için tasarlanmış düşmanca istemlere karşı dayanıklılığını test etme.
- Halüsinasyonlar: Modelin olgusal olarak yanlış veya uydurma bilgiler ürettiği durumları değerlendirme.
- Talimat Hiyerarşisi: Modelin talimatların önceliklendirilmesine ne kadar uyduğunu ölçme, geliştirici mesajları yerine sistem mesajlarını ve kullanıcı mesajları yerine geliştirici mesajlarını takip etmesini sağlama
OpenAI, bu değerlendirmeleri paylaşarak, AI güvenliğini artırmak ve alandaki en iyi uygulamaların iş birliğine dayalı olarak geliştirilmesini teşvik etmek için topluluk çabalarını desteklemeyi amaçlıyor.
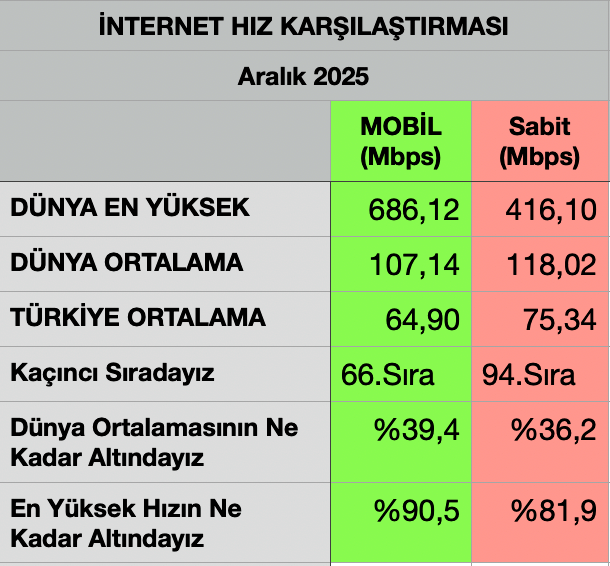 Kaynak :
Kaynak : 