Oxford araştırmacıları tarafından yürütülen bir çalışmaya göre, büyük dil modelleri (LLM’ler), kullanıcıya göre performans gösteriyor. Modeller teknik olarak uzman seviyesine yakın tanı koyabilse bile, bu sürecin zayıf halkası “insan yönlendirmesi”. Yani LLM tek başına test edildiğinde, bir insan tarafından yönlendirilmesine nazaran neredeyse 3 kat daha doğru tanı koyuyor. Peki yapay zeka kullandığımızda doğru tanıyı nasıl bileceğiz?
Test senaryoları (semptomlar veya vaka açıklamaları gibi) doğrudan LLM’ye temiz ve yapılandırılmış bir biçimde verildiğinde, model tıbbi durumları %94,9 oranında doğru bir şekilde tanımladı. İnsan kullanıcılar LLM’ye aynı senaryoları kendi sözcükleriyle (doğal tereddütler, tutarsızlıklar veya belirsizlikler dahil) sorduğunda, modelin doğruluğu keskin bir şekilde %34,5’e düştü.
Yani makineler verilerle hareket ettiğinde daha doğru sonuçlar çıktı. Sıradan insanlar ise önemli semptomları atlayabilir, gerçekleri yanlış ifade edebilir veya soruları yanıltıcı şekillerde ifade edebilir.
LLM duyarlılığı: Modelin performansı, sorunun nasıl çerçevelendiğine büyük ölçüde bağlıdır.
Çalışmanın özetinde şunlar veriliyor;
“Küresel sağlık hizmeti sağlayıcıları, halka tıbbi tavsiye sağlamak için büyük dil modelleri (LLM) kullanımını araştırıyor. LLM’ler artık tıp lisanslama sınavlarında neredeyse mükemmel puanlar alıyor, ancak bu gerçek dünya ortamlarında doğru performans anlamına gelmiyor.
LLM’lerin, halkın altta yatan koşulları belirlemesine ve 1.298 katılımcının yer aldığı kontrollü bir çalışmada on tıbbi senaryoda bir eylem yolu (eğilim) seçmesine yardımcı olup olamayacağını test ettik. Katılımcılar, bir LLM’den (GPT-4o, Llama 3, Command R+) veya kendi seçtikleri bir kaynaktan (kontrol) yardım almak üzere rastgele atandılar. Tek başlarına test edilen LLM’ler, senaryoları doğru bir şekilde tamamlayarak vakaların %94,9’unda koşulları ve %56,3’ünde eğilimi doğru bir şekilde belirlediler. Ancak aynı LLM’leri kullanan katılımcılar, vakaların %34,5’inden azında ilgili koşulları ve %44,2’sinden azında eğilimi belirlediler; her ikisi de kontrol grubundan daha iyi değildi.
Kullanıcı etkileşimlerini, tıbbi tavsiye için LLM’lerin dağıtımında bir zorluk olarak tanımlıyoruz. Tıbbi bilgi ve simüle edilmiş hasta etkileşimleri için standart ölçütler, insan katılımcılarda bulduğumuz başarısızlıkları öngörmez. İleriye dönük olarak, sağlık hizmetlerinde kamuya açık dağıtımlardan önce etkileşimli yetenekleri değerlendirmek için sistematik insan kullanıcı testi öneriyoruz.”
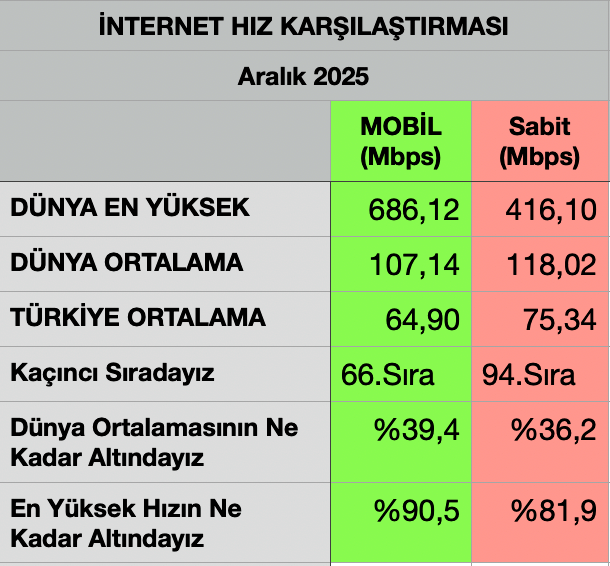 Kaynak :
Kaynak : 