
Google, web sitesi yayıncılarına, verilerinin şirketin yapay zeka modellerini eğitmek için kullanılmasını devre dışı bırakma ve Google Arama yoluyla erişilebilir kalma olanağı sağladığını duyurdu. Google-Extulated adı verilen yeni araç, sitelerin Googlebot gibi tarayıcılar tarafından alınıp dizine eklenmesine olanak tanırken, zaman içinde gelişen yapay zeka modellerini eğitmek için sitelerin verilerinin kullanılmasını da engelliyor.
Şirket, Google-Extulated’in yayıncılara “sitelerinin Bard ve Vertex AI üretken API’lerini geliştirmeye yardımcı olup olmadığını yönetmelerine” olanak tanıyacağını ve web yayıncılarının “bir sitedeki içeriğe erişimi kontrol etmek” için bu düğmeyi kullanabileceğini belirtti. Google, temmuz ayında AI sohbet robotu Bard’ı web’den alınan halka açık veriler üzerinde eğittiğini doğruladı.
Google-Extulated’e, web tarayıcılarına belirli sitelere erişip erişemeyeceklerini bildiren metin dosyası olarak da bilinen robots.txt aracılığıyla ulaşılabilir. Google, “AI uygulamaları genişledikçe” “web yayıncıları için seçim ve kontrole yönelik makine tarafından okunabilen ek yaklaşımları” keşfetmeye devam edeceğini ve yakında paylaşacak daha fazlasının olacağını belirtiyor.
Aralarında The New York Times , CNN, Reuters ve Medium’un da bulunduğu birçok site, OpenAI’nin veri toplamak ve ChatGPT’yi eğitmek için kullandığı web tarayıcısını engellemek için şimdiden harekete geçti. Ancak Google’ın nasıl engelleneceği konusunda endişeler vardı. Sonuçta web siteleri Google’ın tarayıcılarını tamamen kapatamaz, aksi takdirde aramada dizine eklenmezler. Bu, The New York Times gibi bazı sitelerin, şirketlerin içeriklerini yapay zekayı eğitmek için kullanmalarını yasaklayacak şekilde hizmet şartlarını güncelleyerek Google’ı yasal olarak engellemesine yol açtı.
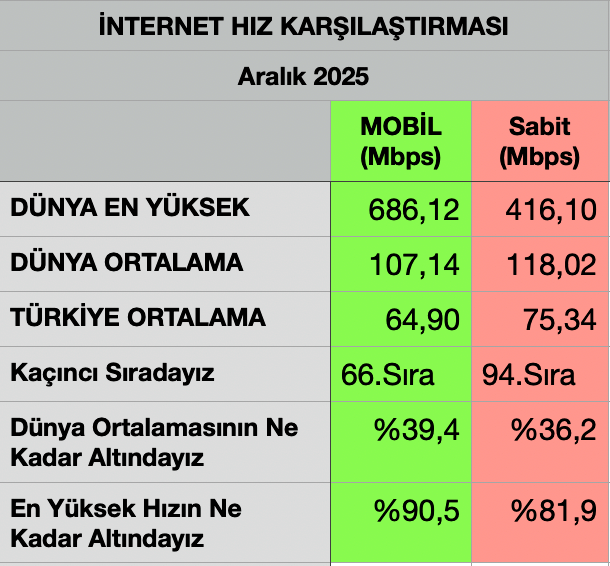 Kaynak :
Kaynak : 