
Nedir Görünmeyen Web ve neden arama motorları (search engines) Görünmeyen Web’in indeksini yapmıyor?
Geniş tabanlı arama motorlarını işletmek büyük bir maliyet unsuru. Web’de yer alan kaynakları bulmak ve bunları zaman içinde güncelleştirmek pahalı bir süreç. Bu yüzden arama motorları bulup getirdikleri ve indeksini yaptıkları Web sitelerini sınırlı tutuyorlar. İndeksi yapılmayan bu sayfalar Görünmeyen Web’i oluşturduğu düşünülse de, aslında değil. Bu siteler görülebilinir ve indeksi yapılabilinir, fakat arama motorları yukarda bahsedilen bilinçli nedenle bu fiili gerçekleştirmiyorlar.
Indeksi yapılamayan sayfalar ve Web’de bulunan fakat arama motorlarının bugünkü teknolojiyle giremediği bilgi kaynakları var. İşte bunlar Görünmeyen Web’i oluşturuyorlar.
Peki neden bazı Web sayfalarının indeksi yapılamıyor? En basit sebebi, arama motorlarının bu sayfalara ulaşabilecek siber bağlantıların (link) olmaması. Yani Web ortamında başka siteler tarafından link verilmiyorsa, arama motorları bu tip sayfalara ulaşamayacaktır. Arama motorlarının indeksleme yapmak için kullandığı örümcek (spider) veya robot diye adlandırılan programlar siber bağlantılar sayesinde diğer Web sayfalarına veya sitelerine ulaşırlar (crawling)**.
Bir diğer neden ise bu tip sayfalar arama motorlarının indeksini yapamadığı grafik, CGI, imaj (image), flash, ses ve PDF dosyaları gibi veri modellerinden oluştuğu içindir. Fakat geçtiğimiz yılın sonbaharında Google, sahip oldugu teknolojiyi geliştirdiğini, dolayısıyla Web sitelerinde bulunan flash tabanlı reklamları okuyabileceğini ve arkasında var olan sitelere ulaşabildiğini açıkladı. Ayrıca artık Google, PDF dosyalarına erişebiliyor. Görünen o ki yakın zamanda mevcut arama motoru teknolojisi gelişecek ve Görünmeyen Web biraz daha görünür hale gelecek.
Fakat Görünmeyen Web’i oluşturan en büyük kısım ise veritabanlari. Robotlar karşılaştıkları veritabanlarının adreslerini alabiliyor, fakat içlerinde bulunan milyonlarca bilgilere ulaşamıyor. Oysa bugün binlerce, belki de milyonlarca veritabanı içerdiği bilgilere ulaşılması için bekliyor. Görünmeyen Web çok büyük ve görünür kısımdan, yani arama motorlarının ulaşabildiği ve indeksini yapabildiği kısımdan daha hızlı büyümekte.
Yazımı bitirmeden önce sizlere, Görünmeyen Web’in hacmi ve özellikleri hakkında, BrightPlanet’in Mart 2000’de yaptığı çalışmaya dayanarak fikir vermek istiyorum:
- Veritabanlarında bulunan kaynaklar arama motorlarının ulaşabildiği bilgilerin 500 katı büyüklüğünde.
- Görünmeyen Web 7500 terabit (terabyte) bilgi barındırırken, görünür kısım sadece 19 terabit bilgi içeriyor.
- Görünmeyen Web 550 milyar döküman barındırırken, görünür kısım 1 milyarı aşkın döküman içermekte.
- İkiyüzbin’i aşkın Görünmeyen Web sitesi mevcut.
- Görünmeyen Web’i oluşturan kaynakların yarısından çoğu konuya özel veritabanlarından oluşuyor.
- Görünmeyen Web’in %95’i halka açık bilgi kaynağı, yani üyelik için ücret almıyorlar.
* Görünmeyen Web (Invisible Web), bazı kaynaklarca Derin Web (Deep Web), diğer kaynaklarda ise Kara Delik (Black Hole) olarak adlandırılır.
** Crawling kelimesinin Türkçe karşılığı emeklemek demektir.
*** Terabit bilgisayar hafiza kapasitesi birimlerinden biridir. Bir terabit bin gigabit’e eşittir.
Yazarın Özgeçmişi:
İnsan Kaynakları Yönetimi lisans eğitimini bitirdikten sonra Uluslararası Ticaret üzerine yüksek lisansını yapan Timurkan, MeZUN.COM’da Araştırma Direktörü olarak görev almaktadır. İlgi alanları online ve offline pazar araştırması, SWOT analiz, görünmeyen Web terminolojisi, Internet 2, arama motorları yönetimi ve optimizasyonudur.
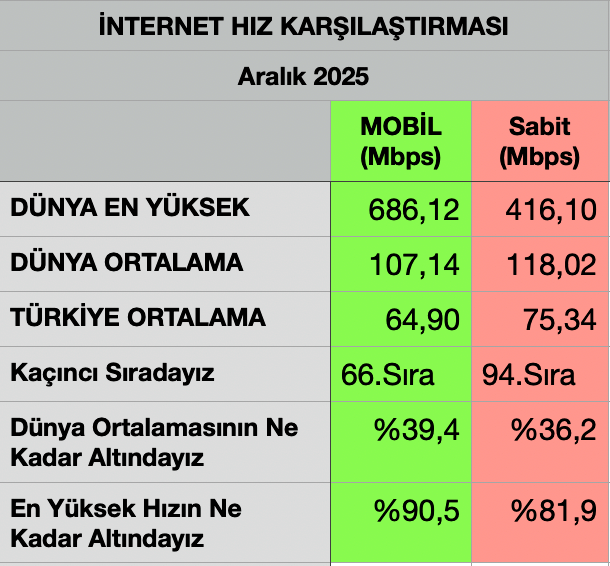 Kaynak :
Kaynak : 