Son dönemde birçok internet sitesi ve dijital yayın platformu, dünyanın farklı bölgelerinden gelen garip trafik hareketleriyle karşı karşıya kalıyor. Özellikle haber siteleri, teknoloji portalları ve içerik odaklı platformlarda; Hong Kong, Vietnam, Endonezya, ABD, Arjantin veya Doğu Avrupa gibi bölgelerden gelen ve çoğu zaman “referral link” içermeyen ziyaretlerde dikkat çekici artışlar gözlemleniyor.
Bu ziyaretlerin önemli kısmı, kategori sayfalarına, etiket arşivlerine, haber listelerine veya ana sayfa yerine içerik kümelerine, bir referans linki ya da ana sayfadan yönlenmeden, doğrudan erişim şeklinde gerçekleşiyor.
Genellikle, ziyaret süresi çok kısa, yalnızca tek sayfa görüntüleniyor, gerçek kullanıcı davranışı görülmüyor ve ziyaretlerin önemli bölümü mobil cihaz gibi davranan sistemlerden geliyor.
Siber güvenlik uzmanları ve web analitiği alanında çalışan araştırmacılar ise bunun sıradan bir trafik hareketi olmayabileceğini söylüyor.
“İnterneti artık sadece insanlar okumuyor”
Uzmanlara göre internet son birkaç yılda büyük bir dönüşüm geçirdi. Eskiden web sitelerini ağırlıklı olarak insanlar ziyaret ederken, bugün trafiğin önemli kısmını, yapay zekâ crawler’ları, veri toplama botları, otomatik indeksleme sistemleri, headless browser ağları ve içerik tarama sistemleri oluşturuyor.
Özellikle büyük dil modellerinin (LLM) yaygınlaşmasıyla birlikte internet, AI sistemleri tarafından sürekli taranan dev bir veri kaynağına dönüşmüş durumda. Bu sistemler çoğu zaman, haber başlıklarını, kategori yapılarını, içerik ilişkilerini, etiket sistemlerini ve yayın akışlarını otomatik olarak analiz ediyor.
Bazı crawler sistemleri yalnızca arama indeksleme amacı taşırken, bazıları ise, yapay zeka eğitim verisi toplama, semantic indexing, içerik özetleme, RAG (Retrieval-Augmented Generation) veri tabanı oluşturma veya medya analizi amaçlı çalışıyor.
Neden özellikle kategori sayfaları hedef alınıyor?
Uzmanlara göre kategori sayfaları, bir sitenin yapısını anlamak için en verimli alanlardan biri. Çünkü bu sayfalar, çok sayıda içeriğe bağlantı içeriyor, yayın sıklığını gösteriyor, konu kümelerini ortaya çıkarıyor ve sitenin semantik haritasını hızlıca çözmeye yardımcı oluyor.
Bu nedenle birçok otomatik sistem önce, “günlük haberler”, “teknoloji”, “ekonomi” veya “gündem” gibi kategori sayfalarını tarıyor. Bazı gelişmiş botlar ise gerçek kullanıcı gibi görünmek için, iPhone, Samsung Galaxy, Android Chrome veya Safari taklidi yapan sahte cihaz kimlikleri kullanıyor.
Gerçek kullanıcı mı, bot mu?
Siber güvenlik uzmanları, modern botların artık klasik “crawler” davranışı göstermediğini belirtiyor. Yeni nesil sistemler, gerçek browser kullanıyor, JavaScript çalıştırıyor, mobil cihaz taklidi yapıyor, VPN veya proxy ağları kullanıyor ve dünyanın farklı ülkelerinden bağlanıyormuş gibi davranabiliyor.
Bu nedenle birçok trafik analizi sistemi artık gerçek kullanıcı ile otomatik sistemi ayırmakta zorlanıyor. Özellikle: “no referrer”, tek sayfalık ziyaret, çok kısa oturum süresi ve dağınık coğrafi erişim gibi davranışlar otomasyon şüphesini artırıyor.
Bu durumun riskleri neler?
Uzmanlara göre bu tür trafik her zaman doğrudan saldırı anlamına gelmiyor. Ancak tamamen zararsız olduğu da söylenemiyor. Özellikle Analytics kirliliği yaratıyor. Sahte trafik yüzünden page view sayılarını şişirebiliyor, bounce rate’i bozabiliyor, gerçek kullanıcı davranışını maskeleyebiliyor ve reklam performans analizlerini yanıltabiliyor.
Bu durumda, reklam gelirleri bot kaynaklı görüntülemeler yüzünden bozulabiliyor. “Invalid traffic”, düşük reklam görünürlüğü ve düşük kaliteli impression sorunlarına yol açabiliyor. Bu durum bazı reklam ağlarında gelir kaybına neden olabiliyor.
En büyük tartışma ise yapay zekâ sistemlerinin içerikleri sessiz biçimde taraması. Bazı uzmanlara göre birçok AI sistemi artık haber sitelerini crawl ediyor, içerikleri özetliyor, semantik veri tabanları oluşturuyor ve kullanıcıya cevabı kendi platformunda sunuyor. Bu da “okuyucu siteye gelmeden içeriğin tüketilmesi” anlamına geliyor.
Reconnaissance ve güvenlik taramaları
Bazı otomatik sistemler ise site altyapısını anlamaya, kullanılan CMS’i tespit etmeye, eklenti açıklarını bulmaya veya güvenlik zafiyetlerini analiz etmeye çalışabiliyor. Uzmanlar, her crawler’ın kötü amaçlı olmadığını ancak bazı keşif taramalarının daha sonra saldırıya dönüşebileceğini söylüyor.
Siteler kendini nasıl koruyabilir?
Uzmanlara göre artık klasik robots.txt dosyası tek başına yeterli değil. Önerilen önlemler arasında, gelişmiş bot koruma sistemleri, Cloudflare benzeri WAF çözümleri, rate limiting, JavaScript challenge sistemleri, AI crawler filtreleme, bot score analizi ve davranışsal trafik incelemeleri yer alıyor.
XMLRPC, açık API uçları, zayıf WordPress eklentileri ve korunmayan admin panelleri özellikle riskli alanlar olarak görülüyor.
Yeni internet düzeni: İnsanlar mı, makineler mi?
Uzmanlara göre internet artık yalnızca insanlar tarafından kullanılan bir ortam değil. Bugün, arama motorları, yapay zekâ sistemleri, veri toplama ağları, reklam teknolojileri ve otomatik analiz platformları interneti sürekli tarayan devasa bir makine ekosistemi oluşturuyor. Bu nedenle birçok yayıncı için artık temel soru “Sitemizi gerçekten insanlar mı okuyor, yoksa makineler mi analiz ediyor?” haline geldi. Ve görünen o ki yapay zekâ çağında bu sorunun cevabı giderek daha karmaşık hale geliyor.
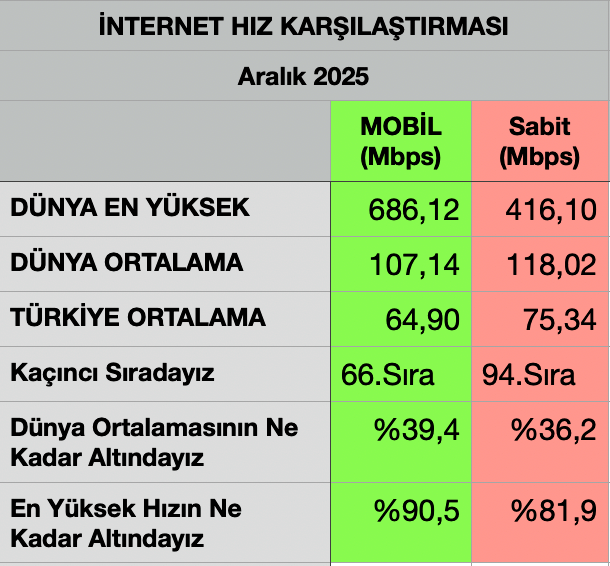 Kaynak :
Kaynak : 