
Açık kaynaklı üretken görüntü aracı Stability AI’nin yaratıcısı Stable Diffusion, Stanfordlu araştırmacıların, internet üzerinde tespit ettiği 1.008+ çocuk cinsel istismar materyalini (CSAM) üretilmesine yardımcı olabileceği anlaşılan bir veri setini yayından kaldırdı. Bu görüntülerin birçoğu küçüklere verilen zararları tasvir ediyor ve uluslararası alanda yasadışı olarak kınanıyor.
Stable Diffusion, Midjourney ve Dall-E gibi büyük dil modelleri ve yapay zeka görüntü oluşturucuları, içeriği eğitmek ve daha sonra oluşturmak için devasa veri kümeleri kullanıyor. LAION-5B gibi bu veri kümelerinin birçoğu internetten alınan görselleri içeriyor.
Stanford araştırmacısı David Thiel şöyle açıkladı :
“Birçok eski model, her tür nesneyi kapsayan 14 milyon görüntüyü içeren, manuel olarak etiketlenmiş ImageNet1 külliyatı gibi veri setleri üzerinden eğitildi. Ancak Stabil Difüzyon gibi daha yeni modeller, LAION-5B2 veri setindeki milyarlarca internetten kazınmış görüntü üzerinden eğitildi. İncelenmemiş taramayla beslenen bu veri seti, önemli miktarda rahatsız edici materyal içeriyor”
Stanford raporuna göre yasa dışı görüntüler, veri kümesindeki bir görüntünün hash değerini bilinen CSAM’den biriyle karşılaştıran algısal ve kriptografik karma tabanlı algılama kullanılarak belirlendi. Hash değeri benzer ise görüntü potansiyel CSAM olarak işaretlenir. Thiel, görüntü oluşturucuları eğitmek için kullanılan veri setlerinin söz konusu görüntüleri içermediğini ancak yine de yasa dışı materyale erişim sağlayabileceğini belirtti.
Thiel şöyle açıkladı :
“Web ölçeğindeki veri kümeleri, güvenlik filtreleme girişimlerine rağmen birçok nedenden dolayı son derece sorunludur. CSAM, potansiyel telif hakkı ve gizlilik endişeleri bir yana, bu tür veri kümelerinde rıza dışı mahrem görüntülerin (NCII) veya ‘sınırda’ içeriğin varlığı esasen kesindir”
Thiel, yapay zeka modellerinin kadınları çıplaklıkla ilişkilendirme eğilimini ve yapay zeka destekli NCII uygulamaları oluşturmanın giderek kolaylaştığını vurguladı. Thiel, LAION gibi veri kümelerinin ve bunlar üzerinde eğitilen modellerin bir kenara bırakılması gerektiği sonucuna vardı.
Thiel, yapay zeka modeli eğitim verilerinde CSAM konusunda alarm verirken, açık kaynak geliştirmenin önemini vurguladı ve bunun küçük bir grup şirket tarafından “geçit denetimli” modellerden daha iyi olduğunu söyledi.
“Bazılarının bu sonuçları açık kaynaklı ML’ye karşı çıkmak için kullanacağını biliyorum, ki benim amacım bu değil. Açık kaynaklı ML’nin birçok sorunu var, ancak bir avuç mega şirket ve zengin hızlandırıcı sürüngenler tarafından korunan ML’nin de sorunları var. Her ikisi de uygun güvenlik önlemleri olmadan aceleyle konuşlandırıldı.”
1 ay kadar önce de İngiltere’de İnternet İzleme Vakfı (IWF), aynı konuda bir rapor yayınladı. IWF’nin raporu, araştırmacıların bir ay boyunca tek bir darkweb çocuk istismarı web sitesinde yapay zeka görüntülerini kayıt altına alarak, İngiliz yasalarına göre yasa dışı sayılabilecek yaklaşık 3.000 yaratılmış görüntü bulduğunu ayrıntılarıyla anlatıyor.
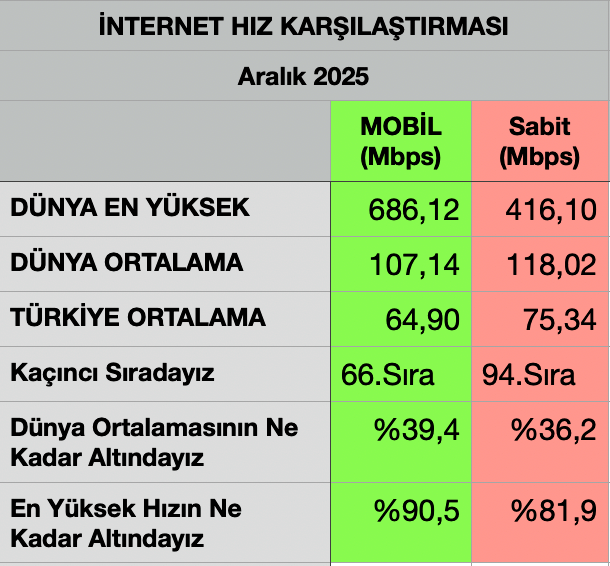 Kaynak :
Kaynak : 