Andrew G. Barto ve Richard S. Sutton, takviyeli öğrenmedeki öncü çalışmalarından dolayı, genellikle “Bilgisayarın Nobel Ödülü” olarak anılan 2024 ACM A.M. Turing Ödülü’ne layık görüldü. Özellikle karar almak için deneyimlerden öğrenen sistemler geliştirmede önemli katkıları bulunuyor. Bu katkıları şöyle özetleyebiliriz;
- Zamansal Fark (TD) Öğrenmesi: Monte Carlo yöntemlerini ve dinamik programlamayı birleştiren, ajanların çevresel modeller olmadan ham deneyimlerden öğrenmelerini sağlayan bir atılım.
- Aktör-Eleştirmen Yöntemleri: Karar alma süreçlerini optimize eden çift ağ çerçeveleri (eylem seçimi için aktör, değerlendirme için eleştirmen).
- Öncü Ders Kitabı: Yapay Zeka eğitimi ve araştırmaları için temel bir kaynak olan “Takviyeli Öğrenme: Bir Giriş (1998)“.
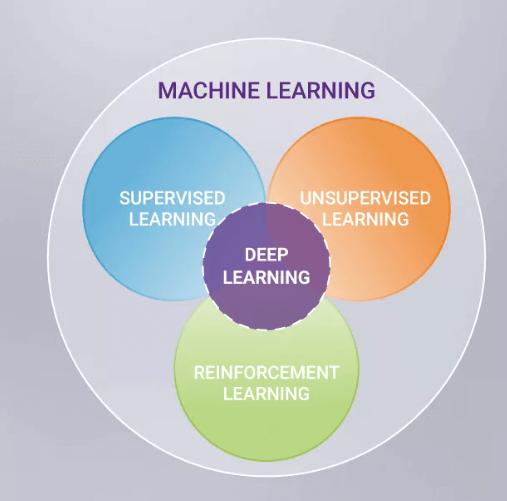
Takviyeli Öğrenme (Reinforcement Learning – RL) Nedir?
Takviyeli öğrenme, ajanların ödüller ve cezalar tarafından yönlendirilen çevreleriyle deneme yanılma etkileşimleri yoluyla optimum davranışları öğrendikleri bir makine öğrenimi dalı. Bu yaklaşım çeşitli yapay zeka ilerlemelerinde etkili oldu. Örneğin;
- Oyun Oynama: Go oyununda en iyi insan oyuncuları yenen Google DeepMind’ın AlphaGo’su, takviyeli öğrenme tekniklerini kullandılar.
- Doğal Dil İşleme: ChatGPT gibi modeller, dil anlayışlarını ve üretim yeteneklerini geliştirmek için takviyeli öğrenmeden faydalandı.
- Robotik ve Otomasyon: Takviyeli öğrenme, robotlara karmaşık görevleri öğretmek ve endüstriyel süreçleri optimize etmek için uygulandı.
İlerlemelere rağmen, Barto ve Sutton, kapsamlı testler yapılmadan yapay zeka modellerinin hızla dağıtılmasıyla ilgili endişe duyduklarını belirtiyorlar. Yapay zeka teknolojilerinin uygun güvenlik önlemleri olmadan piyasaya sürülmesinin öngörülemeyen olumsuz sonuçlara yol açabileceği konusunda uyararak, sorumlu ve iyi düzenlenmiş geliştirmenin önemine işaret ettiler.
Barto ve Sutton Kimdir?
Massachusetts Amherst Üniversitesi’nde Emeritus Profesör olan Andrew G.Barto’nun araştırmaları, makine öğrenimi ve sinir ağları dahil olmak üzere otonom ajanlarda öğrenmeye odaklanmıştır.
Alberta Üniversitesi’nde profesör ve Keen Technologies’de araştırma bilimcisi olan Richard S.Sutton’ın çalışmaları ise takviyeli öğrenme alanını önemli ölçüde etkilemiştir.
Barto ve Sutton’ın RL’deki temel çalışmaları, AI’nın teorik modellerden gerçek dünya uygulamalarına geçişinde önemli rol oynamıştır. Turing Ödülü tanınması, modern AI’yı şekillendirmedeki rollerini vurgulayarak, uyarlanabilir ve otonom bir şekilde öğrenen sistemleri mümkün kılmaktadır. Mirasları, RL’yi yapay zekanın temel taşı olarak pekiştirerek sektörler genelinde inovasyonu yönlendirmeye devam etmektedir.
 Kaynak :
Kaynak : 