Tüm internet için önemli bir uyarı işareti meydana geldi. Wikipedia’yı yöneten Wikimedia Vakfı, yapay zeka botlarının (yapay zeka şirketlerinin web tarayıcıları) sunucularını aşırı yüklediğini açıkladı. Wikimedia Vakfı, yapay zeka bot trafiğinde önemli bir artış olduğunu ve otomatik tarayıcıların artık sunucu kaynaklarının %65’ini tükettiğini bildirdi. Bu akış, platformun altyapısını zorluyor ve meşru kullanıcılar için daha yüksek operasyonel maliyetlere ve daha yavaş yanıt sürelerine yol açıyor.
Çoğu, ChatGPT, Gemini, Claude ve diğerleri gibi büyük dil modelleri (LLM’ler) eğitmek için Wikipedia’yı tarayan yapay zeka şirketlerinden geliyor. Wikimedia’nın sunucuları zorlanıyor. Vakıf, bant genişliği ve sunucu kapasitesi için milyonlarca dolar harcıyor ve bot trafiğindeki artış, kaynakları insan kullanıcılardan uzaklaştırıyor. Wikimedia, hız sınırlama ve daha katı bot politikaları uyguladı, ancak bazı tarayıcılar insan davranışını taklit ederek veya IP’leri döndürerek tespit edilmekten kaçınıyor.
Herkes için ücretsiz olan Wikimedia’yı çalıştırmak pahalı. Botlar hiçbir şey ödemeden büyük kaynaklar kullanıyor. Sorulan bilgiler için Wikipedia’da bilgi tarıyorlar. Bu da sitenin trafiğini mahvediyor. Maliyetler patlıyor. Daha fazla bot = daha fazla sunucu yükü = bant genişliği ve altyapı için daha fazla paraya ihtiyaç var ve yapay zeka vermeden alıyor.
Wikipedia bağışlarla ayakta duran bir kar amacı gütmeyen kuruluşken, yapay zeka şirketleri Wikipedia’nın ücretsiz bilgisini kullanarak milyarlar kazanıyor. Bot trafiği artmaya devam ederse, Wikipedia gerçek kullanıcılar için daha yavaş veya hatta dengesiz hale gelebilir. Wikimedia bot erişimini sınırlamayı veya yasaklamayı düşünüyor, ancak tartışmalar var:
- Wikipedia açıklığa dayanıyor.
- Yapay zeka şirketleri erişim için ödeme yapmalı mı?
- Wikimedia kötü botları engellemeli mi?
Durum, AI şirketlerinin ticari AI eğitiminde kullanılan veriler için açık erişim platformlarına tazminat verip vermemesi gerektiği konusundaki tartışmaları yeniden alevlendiriyor.
Sadece Wikimedia Değil
Wikimedia Vakfı bu zorlukla karşı karşıya kalan tek kuruluş değil; AI bot trafiği ve yetkisiz veri toplama, kamuya açık verilere ev sahipliği yapan birçok çevrimiçi platform için büyük bir sorun haline geliyor. Diğer platformların benzer sorunlarla nasıl başa çıktığı ve yaklaşımlarının nasıl karşılaştırıldığı şöyle:
1. Reddit: Ödeme Duvarları ve API Protestoları : Reddit uzun zamandır AI eğitim verileri için bir altın madeni (özellikle konuşma modelleri için). 2023’te API fiyatlandırmasını önemli ölçüde artırdı ve ücretsiz erişime güvenen birçok üçüncü taraf veri toplayıcıyı ve AI firmasını etkili bir şekilde devre dışı bıraktı.
Reddit artık AI şirketlerinden veri erişimi için ücret alıyor (örneğin, Google’ın Reddit içeriği için yılda 60 milyon dolar ödediği bildiriliyor). API değişiklikleri protestolara yol açtı (örneğin, subreddit karartmaları), ancak Reddit kısıtlanmamış erişimden ziyade karlılığa öncelik vererek kararlılığını korudu. Gelir açısından kısa vadeli bir kazanç, ancak topluluğuyla uzun vadeli gerginlikler.
Wikimedia ile karşılaştırma: Reddit kâr odaklıdır, bu nedenle ödeme duvarlarını uygulayabilir. Kâr amacı gütmeyen bir kuruluş olan Wikimedia, ücretsiz bilgi misyonundan ödün vermeden erişimi kolayca paraya çeviremez.
2. Stack Overflow: Kazıyıcıları Engelleme ve Lisanslama Savaşları : Stack Overflow’un Soru-Cevap verileri, kodlama yapay zekalarını eğitmek için yaygın olarak kullanılmıştır (örneğin, ChatGPT, GitHub Copilot). 2023’te platform, yıllarca kontrolsüz kazıma işleminin ardından GPTBot’u (OpenAI’nin tarayıcısı) engelledi.
Yapay zeka şirketlerinin verileri lisanslamasını veya resmi olarak ortaklık kurmasını gerektiriyor. 2024’te OpenAI ile bir anlaşma duyurdu—ancak kullanıcılar katkıda bulunanlara atıf/tazminat eksikliğinden dolayı isyan etti. aha küçük AI firmaları uyabilir, ancak büyük oyuncular (OpenAI gibi) özel anlaşmalar müzakere eder.
Wikimedia ile karşılaştırma: Stack Overflow’un merkezi mülkiyeti, şartları daha agresif bir şekilde uygulamasını sağlar. Wikimedia’nın açık düzenleme modeli kontrolü zorlaştırır.
3. Haber Yayıncıları: Davalar ve Lisans Anlaşmaları : Medya kuruluşları (örn. NYT, CNN) AI firmalarına ödeme yapmadan makaleleri topladıkları için dava açtı. New York Times v. OpenAI davası telif hakkı sorumluluğu için bir emsal oluşturabilir. Bazı yayıncılar AI eğitimi için geriye dönük ödeme talep ediyor. Diğerleri (örn. Axel Springer) içerik için OpenAI ile anlaşmalar imzalıyor. Mücadele eden yayıncılar ile kar edenler arasında büyüyen bir bölünme.
Wikimedia ile karşılaştırma: Haber siteleri içeriklerinin sahibidir; Wikimedia’nın CC-BY-SA lisansı yeniden kullanıma izin verir (atıfta bulunularak). Ancak açık lisanslar altında bile ölçek ve kaynak kötüye kullanımı sorun olmaya devam ediyor.
4. Sosyal Medya: Oran Sınırları ve Gölge Yasaklama Botları : Twitter (X), Facebook ve Instagram, AI tarafından yönlendirilen spam/kazıma ile karşı karşıya. Elon Musk’ın X’i, Oran sınırları, tarama için ödeme politikaları (API erişimi için ayda 42.000 $). Şüpheli trafiği tespit etmek ve sınırlamak için AI kullanır. Kazıma azaltıldı ancak araştırmacılara ve üçüncü taraf uygulamalara da zarar verdi.
Wikimedia ile karşılaştırma: Sosyal platformların soruna atacak daha fazla altyapı $$’sı var. Wikimedia’nın kâr amacı gütmeyen bütçesi ölçeklemeyi zorlaştırıyor.
Bu duruma Olası Çözümler:
Toplu lisanslama havuzları (örneğin, platformlar AI şirketleriyle pazarlık yapmak için bir araya gelir).
Zorunlu atıf (örneğin, Stack Overflow’un talep ettiği gibi kaynakları gösteren AI çıktıları).
Kamu AI finansman modelleri (açık veri sağlayıcılarını desteklemek için AI karlarına vergi mi?).
NYT v. OpenAI gibi davalar AI şirketlerini veri için ödeme yapmaya zorlayabilir.
Teknik Silahlanma Yarışı: Daha iyi bot tespiti (örneğin, AI trafiğinin parmak izi) ve kaçamak tarama.
Topluluk Tepkisi: Daha fazla platform Reddit’in ödeme duvarı modelini takip edebilir ve bu da açık web kültürünün parçalanma riskini doğurabilir.
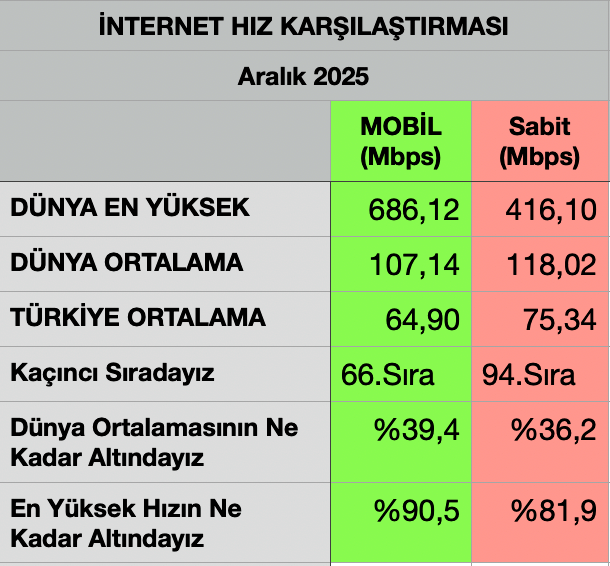 Kaynak :
Kaynak : 